kubernetes
[따배쿠] Kubernetes Autoscaling - 운영
bbiyak2da
2025. 1. 19. 15:45
Metric Server

Metric server 설치
[Metric Server 설치]
root@master:~/Getting-Start-Kubernetes/18# git clone https://github.com/237summit/kubernetes-metrics-server.git
Cloning into 'kubernetes-metrics-server'...
remote: Enumerating objects: 25, done.
remote: Counting objects: 100% (25/25), done.
remote: Compressing objects: 100% (24/24), done.
remote: Total 25 (delta 9), reused 9 (delta 1), pack-reused 0 (from 0)
Receiving objects: 100% (25/25), 5.48 KiB | 5.48 MiB/s, done.
Resolving deltas: 100% (9/9), done.root@master:~/Getting-Start-Kubernetes/18# ls
deploy_web.yaml hpa_web.yaml kubernetes-metrics-serverroot@master:~/Getting-Start-Kubernetes/18# cd kubernetes-metrics-serverroot@master:~/Getting-Start-Kubernetes/18/kubernetes-metrics-server# kubectl apply -f .
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
serviceaccount/metrics-server created
deployment.apps/metrics-server created
service/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
[Metric Server 확인]
root@master:~/Getting-Start-Kubernetes/18/kubernetes-metrics-server# kubectl get deploy -A
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
default my-nginx 2/2 2 2 11d
kube-logging elasticsearch-client 1/1 1 1 10d
kube-logging elasticsearch-master 1/1 1 1 10d
kube-system calico-kube-controllers 1/1 1 1 11d
kube-system coredns 2/2 2 2 11d
kube-system metrics-server 1/1 1 1 113s
Pod 및 Service 생성

[Pod 및 Service 생성]
root@master:~/Getting-Start-Kubernetes/18# vi deploy_web.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-web
spec:
replicas: 1
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: smlinux/hpa-example
name: web
ports:
- containerPort: 80
resources:
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: svc-web
spec:
ports:
- port: 80
targetPort: 80
selector:
app: web
[Pod 및 Service 확인]
root@master:~/Getting-Start-Kubernetes/18# kubectl get deploy,service
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/deploy-web 1/1 1 1 94s
deployment.apps/my-nginx 2/2 2 2 11d
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 11d
service/svc-web ClusterIP 10.100.59.214 <none> 80/TCP 94s
Horizontal Pod Autoscaler 생성
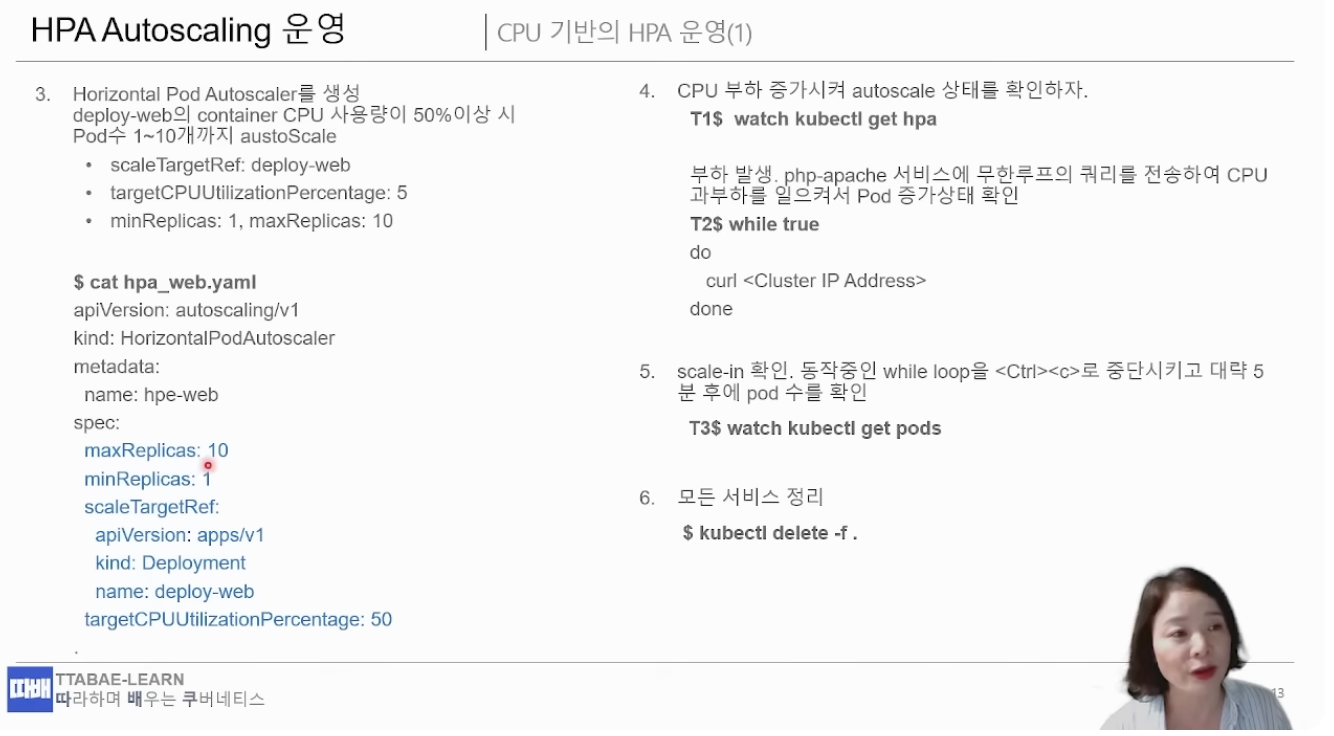
[Horizontal Pod Autoscaler 생성]
root@master:~/Getting-Start-Kubernetes/18# vi hpa_web.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: hpe-web
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: deploy-web
targetCPUUtilizationPercentage: 50
CPU가 50% 넘기면, Replicas를 최소 1개에서 10개까지 자동으로 scaling 요청
root@master:~/Getting-Start-Kubernetes/18# kubectl apply -f hpa_web.yaml
horizontalpodautoscaler.autoscaling/hpe-web created
[확인]
root@master:~/Getting-Start-Kubernetes/18# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpe-web Deployment/deploy-web cpu: <unknown>/50% 1 10 1 30s
[무한루프 실행]

무한루프를 실행해서 CPU 부하를 가한다.
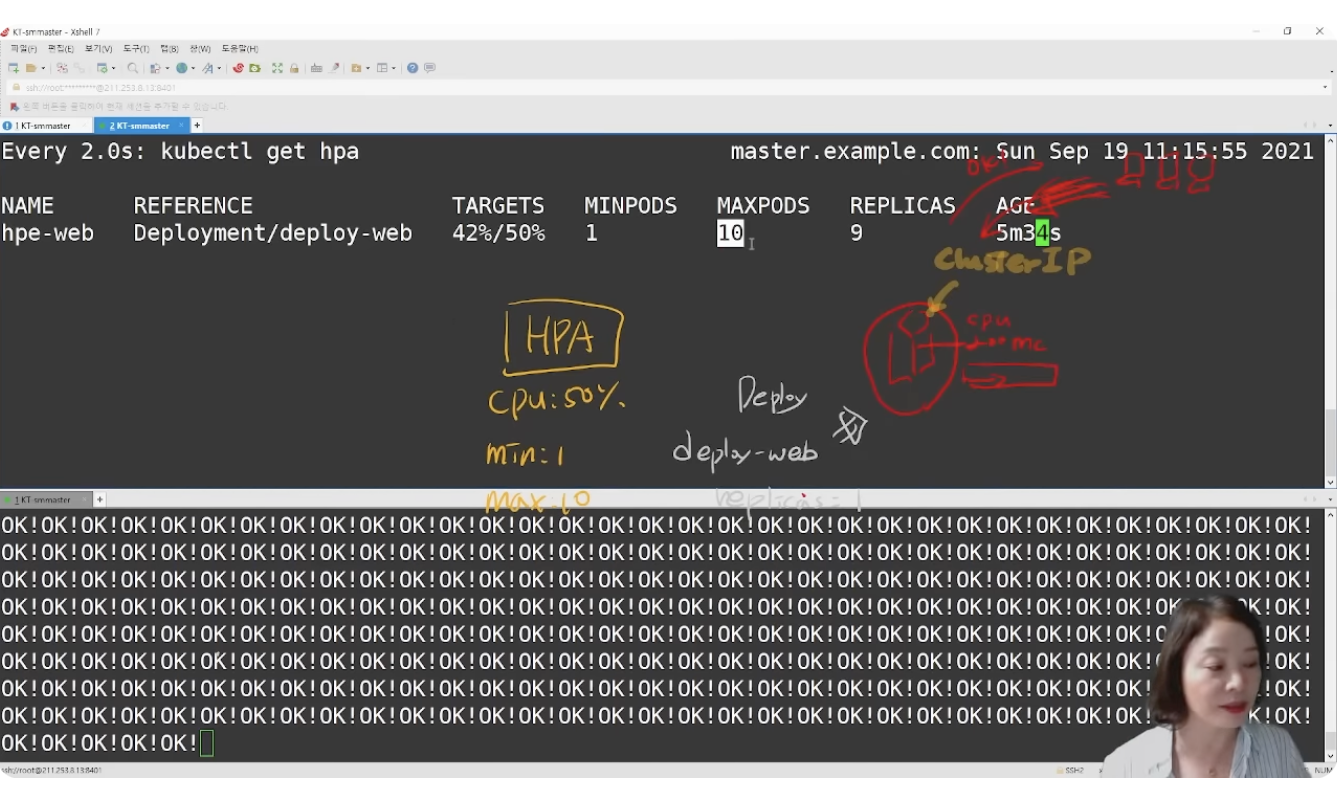
HPA를 통해 Pod가 Scale in 된 것을 확인
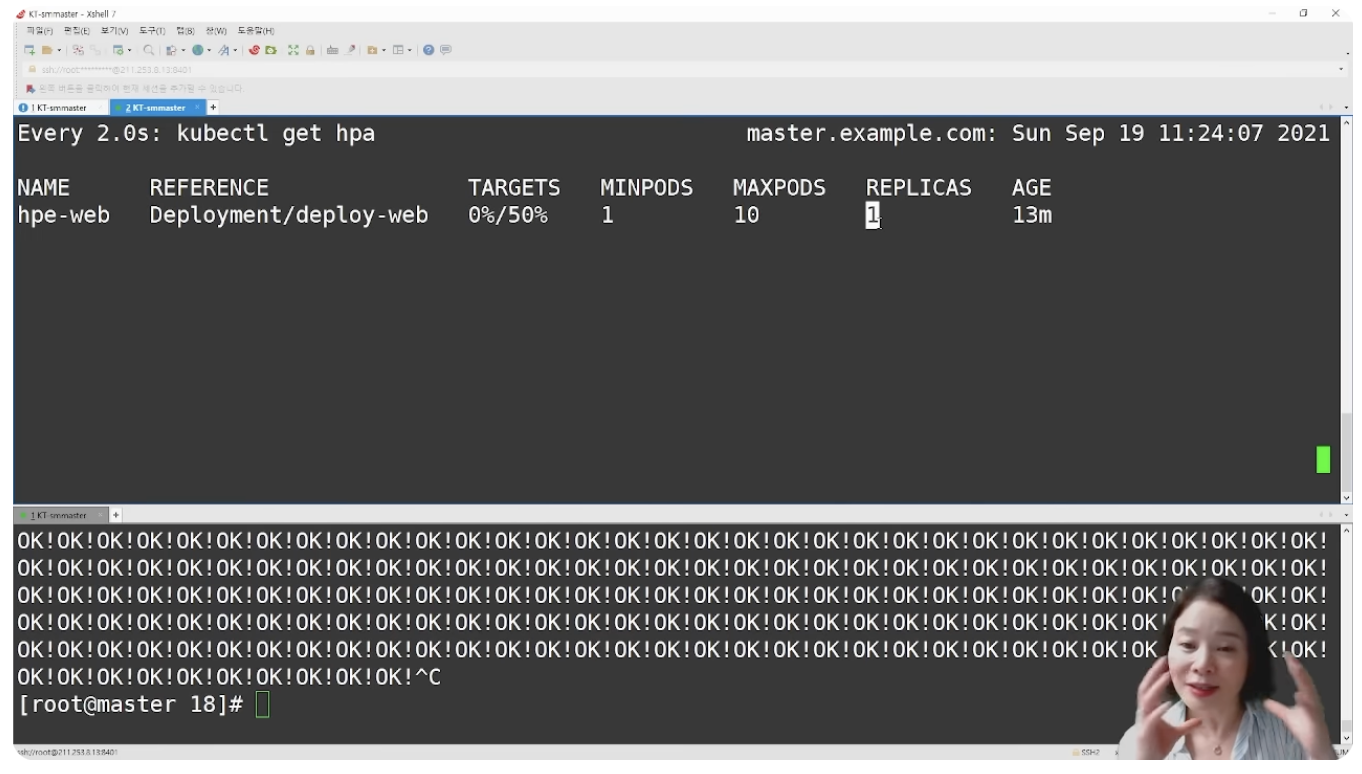
무한루프 실행을 멈추면 CPU가 감소하고 다시 Scale Out
Scale in 되면 5분 대기 후 작동
[참고 영상]
https://www.youtube.com/watch?v=gaYBOH-obJA&list=PLApuRlvrZKohLYdvfX-UEFYTE7kfnnY36&index=11